
Table of Contents
This post has two goals:
- use a hypothetical town with curious residents to give some intuitive understanding of the notion of entropy (of finite partitions or of discrete random variables).
- give some examples of using well known intuitive properties of entropy to prove some less trivial facts about entropy rather than directly using the definition.
Also, while this post is not about ergodic theory and ergodic theory (and measure theory) is not a requirement for most of this post, I include a section for helping students of ergodic theory see how probability theory intuitions can help guide them.
This is not about entropy in thermodynamics (in physics), but about entropy in information theory (in mathematics). (but the two are related).
Notion of the metric entropy of a dynamical system and differential entropy of a continuous probability distribution is also briefly discussed. The notion of entropy rate of a process too.
1. entropy for dummies
1.1. definition of entropy of r.v. and joint entropy
You probably heard that the entropy of a discrete random variable 



where 


Also, given two discrete random variables 

where 

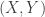
Some graphs that might help:
1.2. the town
Let me give you a (possibly flawed in some way) story that will demonstrate the intuition behind entropy. It will also demonstrate the main properties of entropy, that is, the main properties will become intuitively plausible results, after you read this story, rather than just being results that follows from calculation.
Imagine a town where very curious residents live. Each month, the mayor of this town throws ten fair coins to generate a random binary sequence of length 10. So we have 10 binary random variables: 







Each month, the mayor generates a random sequence of length 10 and then reveals the outcome to Bob who is an employee of the town’s local government. Alice, another employee, sells various tickets for accessing total or partial information about the sequence. Here is how these tickets are supposed to be used: if you are a resident of this town and you want to know the value of
Suppose the price of a ticket for 


Not interesting so far, but how about this random variable. We define the random variable 




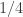




What about the cost of a ticket for 



1.3. intuition for entropy and its properties
One way of justifying the formula in the definition of entropy is to think of it as the only formula that guarantees many plausible properties of entropy that you expect.
For a (discrete) random variable 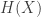
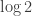

(decomposition property) 
(triangle inequality for entropy) 
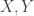
(positivity) 
(normalization) 
(continuity) each 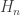
Remember the ticket which cost 
(entropy of equidistribution) 
(upper bound) If 
(w.r.t. independence) 
(monotonicity) 

Having listed all these properties, some understanding emerges:
1.4. intuition for the notion of surprisal
A more direct way to have some intuitive sense of the entropy formula for 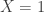
If 

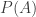
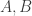



The additive property is this: at first, you knew nothing about the value of the binary sequence (hence, you had zero amount of information as to what the value of the random binary sequence was), and then you heard that some event 




Yes, it does. That in turn justifies the formula for surprisal.
Back to the definition of
2. intuition for conditional entropy and its definition and properties
The theory of entropy is not complete without the notion of conditional entropy. For two (discrete) random variables 
(positivity) 
(upper bound from unconditioning) 
(chain rule) 
Intuition for chain rule is that learning the value of 
The chain rule can also be thought of as a way to express conditional entropy in terms of unconditional entropy: 



Other properties:
(chain rule 2) 


(monotonicity) 


(monotonicity 2) 
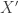
3. entropy of continuous probability distribution
Visit Wikipedia article on differential entropy to see its definition. Here is something that may hook your interest in differential entropy: many probability distributions you may know such as uniform distribution, normal distribution, exponential distribution, geometric distribution, can be characterized as distributions that maximize entropy under certain constraints. For the math-savvy, “Probability distributions and maximum entropy” by Keith Conrad is a good start. As for why and how maximum entropy distributions tend to show up in nature (for example, Maxwell–Boltzmann distribution), perhaps statistical mechanics textbooks have some answers, but not my area of expertise.
3.1. some intuition for differential entropy
Its translation invariance embodies the intuition that knowing that some value is between 1.0 and 1.1 is same amount of information as knowing some value is between 10.0 and 10.1.
The way differential entropy responds to scaling of continuous random variables embodies the intuition that knowing that some value is between 0 and 0.1 is one bit more information than knowing that some value is between 0 and 0.2.
4. for students of ergodic theory (optional reading)
4.1. entropy of a partition
If you are learning ergodic theory, you will at point or have learned that when 

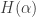






Side note: Another good way of defining 



Further observations on correspondence between partitions and random variables: If 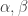



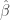






These trivial observations combine together and lead to the following non-trivial insight: The pairing of a dynamical system and a partition 
4.2. comparison between metric entropy and differential entropy
For those who are learning about metric entropy or differential entropy, let’s list some differences for purpose of notes.
While differential entropy concerns continuous probability distributions (on the n-dimensional space), metric entropy concerns fractal-like probability distributions from stochastic processes or invariant measures on a dynamical system. Differential entropy can be negative while metric entropy cannot be. Metric entropy can be described as a conditional entropy, but I am not sure if differential entropy can be too.
As for how they react to forming a convex combination of two probability distributions, the map from continuous probability distributions to their differential entropy is a concave map, but the map from stationary processes or invariant measures (on a system) to their metric entropy is an affine map.
5. using properties of entropy in proofs
5.1. if two random variables are close to each other, then how much are their entropies close to each other?
Let’s say 






To prove E10, we only need to build a random variable 




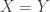





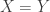



5.2. entropy with respect to convex combination
(only for students of ergodic theory)
Given two invariant probability measures 



(Fact 1) 

(Fact 2) (if you know metric entropy) 
Above two facts follow easily from this Fact 3: the difference 
![[0, H_2(p_1, p_2)]](https://s0.wp.com/latex.php?latex=%5B0%2C+H_2%28p_1%2C+p_2%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)
We want to prove Fact 3 using only basic properties of entropy. How can we employ probabilistic intuition to guide us to find such a proof? The expression 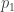
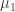
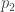

The shared sample space will be a weighted disjoint union of of 

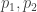

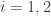








E30 is then equal to 

![[0, H_{\bar\mu}(\gamma)]](https://s0.wp.com/latex.php?latex=%5B0%2C+H_%7B%5Cbar%5Cmu%7D%28%5Cgamma%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)
6. exercises
All of the exercises here can be and should be solved by just using properties of entropy listed in this post instead of directly invoking the entropy formula.
Exercise 10. (useful upper bound) Suppose you have a (discrete) random variable 


Exercise 15. (useful upper bound 2) Suppose you have a (discrete) random variable 

Exercise 20. (useful lower bound) Prove 
Exercise 30. Prove 

Exercise 40. Show 
Exercise 50. (only for students of ergodic theory) Given a measure preserving transformation on a Lebesgue space with positive entropy, and given a positive number less than the positive entropy, show that the system has a factor system with its entropy equal to the given positive number. Should we assume the system has no atoms?
Footnotes:
Properties related to the notion of conditional independence.

Pingback: Intuitions on problems from Elements of Information Theory Chapter 2 | Yoo Box