
prettify-symbols-mode is a recent feature of Emacs and it’s very nice. And it looks like it can replace TeX-fold-mode in the future. But, at the time of writing, prettify-symbols-mode doesn’t seem to work well with AUCTeX unless you enable two workarounds together.
Tested versions:
- AUCTeX 11.89.7 (latest version from GNU ELPA)
- GNU Emacs 25.1
Usual way to enable pretty symbols
If you want to enable it for elisp buffers, you can add:
(add-hook 'emacs-lisp-mode-hook 'prettify-symbols-mode)
Then something like (lambda () (blah)) in elisp buffers should display as (λ () (blah)).
If you want to enable it also for other lisp buffers, scheme mode buffers etc, you can adjust the following code:
(dolist (mode '(scheme emacs-lisp lisp clojure)) (let ((here (intern (concat (symbol-name mode) "-mode-hook")))) ;; (add-hook here 'paredit-mode) (add-hook here 'prettify-symbols-mode)))
If you want to enable for all buffers, you can add:
(global-prettify-symbols-mode 1)
And then for major modes of your interest, you may want to adjust the buffer-local prettify-symbols-alist accordingly, following the simple example code you can find from the documentation for prettify-symbols-mode.
Expected way to use with AUCTeX
Following code may be expected to work:
(add-hook 'TeX-mode-hook 'prettify-symbols-mode)
If it works, then \alpha, \beta, \leftarrow and so on should display as α, β, ←, … for TeX file buffers. I do not doubt that it will just work fine in future versions of AUCTeX, and if you are reading this as an old article, it is possible that just upgrading your AUCTeX package may be enough to make that line work as you expected. If it doesn’t work, then try making the following two changes.
First change
Instead of adding to the hook directly, try adding a delayed version, like so:
(defun my-delayed-prettify () (run-with-idle-timer 0 nil (lambda () (prettify-symbols-mode 1)))) (add-hook 'TeX-mode-hook 'my-delayed-prettify)
This way, (prettify-symbols-mode 1) is guaranteed to run after the style hooks and not before. I don’t know what style hooks do, but it looks like they may reset/erase font-lock stuff you have set up.
If pretty symbols still don’t show up in AUCTeX buffers, then try adding the following change, in addition to the above change.
Second change
This one isn’t really about adding something. It is about removing. Remove the following line from your dotemacs if any:
(require 'tex)
tex.el will load anyway if you visit a TeX file with Emacs. This is a strange change to make, indeed.
You should also remove the following line that is commonly used with miktex users:
(require 'tex-mik)
tex-mik.el is a good small library but tex-mik.el loads tex.el. Feel free to copy parts of tex-mik.el and paste to your dotemacs if you want.
You can ensure you have removed every call of (require ‘tex) from your dotemacs by appending the following line to the end of dotemacs and then restarting Emacs to see if the warning message shows up:
(if (featurep 'tex) (warn "(require 'tex) is still somewhere!"))
If there was some code in dotemacs that relied on the fact that (require ‘tex) was called before, then you have to wrap that code with the with-eval-after-load macro, like this:
(with-eval-after-load 'tex
(add-to-list 'TeX-view-program-selection '(output-pdf "SumatraPDF"))
(add-to-list 'TeX-view-program-list
`("SumatraPDF"
my--sumatrapdf)))
 is placed at position
is placed at position 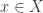 . The cost of moving this particle to a new position
. The cost of moving this particle to a new position  is defined to be
is defined to be  . With this definition, you see:
. With this definition, you see:
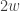 at position x is and should be cost-wise equivalent to two particles each of mass
at position x is and should be cost-wise equivalent to two particles each of mass  at the same position x.)
at the same position x.)
 .
.
 and is placed at
and is placed at 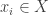 . Since the total mass is 1, we require
. Since the total mass is 1, we require 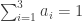 . The mass distribution of this configuration may be written as
. The mass distribution of this configuration may be written as 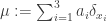 where
where 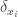 denotes the Dirac delta function centered at
denotes the Dirac delta function centered at  . (Alternatively, you could interprete the sum
. (Alternatively, you could interprete the sum 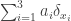 to mean a formal sum, or use Dirac measures instead.)
to mean a formal sum, or use Dirac measures instead.)
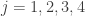 , there is a particle of mass
, there is a particle of mass 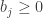 at position
at position 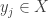 . The mass distribution of this configuration may be written as
. The mass distribution of this configuration may be written as  .
.
 , we split the particle of mass
, we split the particle of mass  at position
at position  . The total number of split particles is now
. The total number of split particles is now 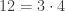 and
and  for each
for each 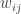 from the old position
from the old position 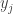 . The total mass of all particles at the new position
. The total mass of all particles at the new position  and we require this to be equal to
and we require this to be equal to 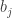 , so that they merge to become a particle of mass
, so that they merge to become a particle of mass 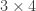 matrix
matrix 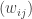 of nonnegative numbers such that
of nonnegative numbers such that 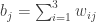 for all j specifies a split-move-merge procedure that transforms the first configuration into the second configuration.
for all j specifies a split-move-merge procedure that transforms the first configuration into the second configuration.
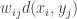 and so the total cost is the sum
and so the total cost is the sum  .
.
 into the second
into the second  and
and  does not depend on how you write
does not depend on how you write  or see two particles at the same position x each of mass
or see two particles at the same position x each of mass 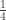 does not affect costs.)
does not affect costs.)
 on
on  . This distribution
. This distribution  is a coupling of
is a coupling of 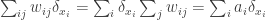 .
.
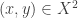 to be an abstract arrow from x to y.
to be an abstract arrow from x to y.
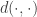 transfers to the triangle inequality for distance between
transfers to the triangle inequality for distance between 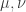 because you can compose a transformation from
because you can compose a transformation from  to get a third transformation from
to get a third transformation from 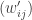 to move the piles again to form
to move the piles again to form  can be obtained by examining percentages of different colors of dirt in each of the final piles of dirt. (the output
can be obtained by examining percentages of different colors of dirt in each of the final piles of dirt. (the output 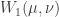 . For general non-discrete probability measures
. For general non-discrete probability measures  , the definition is done using couplings of
, the definition is done using couplings of 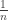 . In the first configuration, the n particles are at the n places
. In the first configuration, the n particles are at the n places  (some of which may be same places). In the second configuration, the new n places are
(some of which may be same places). In the second configuration, the new n places are  . It is known that in this case there is always a split-move-merge procedure (between the two configurations) that minimizes the cost but also skips the split and the merge steps. The procedures without the split and merge steps are specified by functions
. It is known that in this case there is always a split-move-merge procedure (between the two configurations) that minimizes the cost but also skips the split and the merge steps. The procedures without the split and merge steps are specified by functions  from
from  to itself. If
to itself. If  (at the cost of
(at the cost of 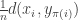 ) for
) for 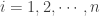 .
.
 to
to  in this case is the same as the minimum of the average
in this case is the same as the minimum of the average  over all permutations
over all permutations  .
.
 doubly stochastic matrix (i.e. a split-move-merge procedure in our case) can be written as a convex combination of permutations.
doubly stochastic matrix (i.e. a split-move-merge procedure in our case) can be written as a convex combination of permutations.
 in an appropriate sense.
in an appropriate sense.
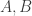 respectively and if
respectively and if 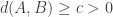 , then the distance between
, then the distance between 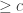 . If we relax to
. If we relax to 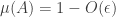 and
and 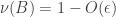 , then we still have the approximate
, then we still have the approximate  .
.
 and if
and if  is such that
is such that  for all x, then
for all x, then 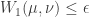 . If we relax to just
. If we relax to just  for all
for all 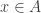 (uniformly) in some big set
(uniformly) in some big set  .
.
 . This is perhaps related to why the central limit theorem works. If you keep adding i.i.d. random variables one by one, the entropy of the sum never decreases. So aside from special cases, we can expect that the entropy would get higher and higher. High entropy of the sum alone may not tell you much about the probability distribution of the sum, but the variance and the mean of the sum is also known, and IIRC the normal distribution maximizes entropy under the constraints on the mean and variance. It does not make a proof of the central limit theorem but I think it illustrates the relation between large degrees of freedom (in statistical mechanics) and probability distributions with maximal entropy.
. This is perhaps related to why the central limit theorem works. If you keep adding i.i.d. random variables one by one, the entropy of the sum never decreases. So aside from special cases, we can expect that the entropy would get higher and higher. High entropy of the sum alone may not tell you much about the probability distribution of the sum, but the variance and the mean of the sum is also known, and IIRC the normal distribution maximizes entropy under the constraints on the mean and variance. It does not make a proof of the central limit theorem but I think it illustrates the relation between large degrees of freedom (in statistical mechanics) and probability distributions with maximal entropy.
 binary random variables
binary random variables  related by one linear equation
related by one linear equation 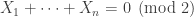 . The given joint probability distribution is in some sense the most fair distribution under the constraint given by the linear equation.
. The given joint probability distribution is in some sense the most fair distribution under the constraint given by the linear equation.
 tells you nothing about
tells you nothing about 
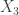
 , knowing
, knowing 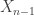 tells you everything about
tells you everything about 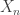 (because of the linear equation).
(because of the linear equation).
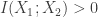 . In fact, you can even choose a distribution so that knowing
. In fact, you can even choose a distribution so that knowing  . That is the case when we choose the most fair distribution under the constraint
. That is the case when we choose the most fair distribution under the constraint 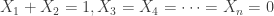 .
.
 about the object are asked, eliciting answers
about the object are asked, eliciting answers 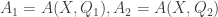 . The problem asks to show that the two questions are less valuable than twice a single question.
. The problem asks to show that the two questions are less valuable than twice a single question.
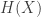 .
.
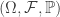 to measurable spaces
to measurable spaces  and
and  respectively. Consider the following three conditions:
respectively. Consider the following three conditions: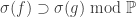 (in other words, each element in
(in other words, each element in  is equivalent (up to null sets) to some element in
is equivalent (up to null sets) to some element in  . The notation
. The notation 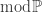 is used when an author wants to make explicit the practice of
is used when an author wants to make explicit the practice of 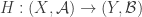 with
with 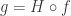 a.e.
a.e. with
with  .
.
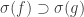 after discarding all points in some null set from
after discarding all points in some null set from  .
.
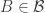 , there is
, there is  such that the symmetric difference
such that the symmetric difference  is a
is a  but is this a null set? Perhaps not.
but is this a null set? Perhaps not.
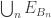 where
where  is a sequence that generates
is a sequence that generates  (Existence of such a sequence is guaranteed by the assumption that
(Existence of such a sequence is guaranteed by the assumption that 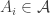 such that
such that 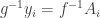 a.e. for each i.
a.e. for each i.
 form a countable partition modulo
form a countable partition modulo  is a null set when
is a null set when  and their union over all i has measure 1, or equivalently that for a.e.
and their union over all i has measure 1, or equivalently that for a.e.  , there exists unique i for which
, there exists unique i for which 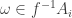 .
.
 form a countable partition mod
form a countable partition mod  behaves like an inclusion map)
behaves like an inclusion map)
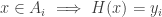 . It is easy to define such an H.
. It is easy to define such an H.
 , we have:
, we have: is in
is in  (by property of H);
(by property of H); (by how
(by how  on this
on this  . There is a measurable
. There is a measurable  with
with  a.e..
a.e..
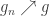 holds everywhere. It would be nice to take
holds everywhere. It would be nice to take 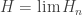 but we only know
but we only know 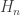 converges at least on
converges at least on  for some subset
for some subset  of measure 1, and we don’t know if this image is measurable.
of measure 1, and we don’t know if this image is measurable.
 for all x for which the limit exists. Such H exists and with this H we can proceed to show
for all x for which the limit exists. Such H exists and with this H we can proceed to show ![[H_n \nearrow]](https://s0.wp.com/latex.php?latex=%5BH_n+%5Cnearrow%5D&bg=ffffff&fg=333333&s=0&c=20201002) (alternatively also
(alternatively also ![[\exists \lim H_n]](https://s0.wp.com/latex.php?latex=%5B%5Cexists+%5Clim+H_n%5D&bg=ffffff&fg=333333&s=0&c=20201002) ) is measurable and so one can show that its measure is 1. Then we set H to be a
) is measurable and so one can show that its measure is 1. Then we set H to be a  is a P-a.e. limit of
is a P-a.e. limit of  . So we can proceed with this H too.
. So we can proceed with this H too.
 is a Lebesgue space (which follows because
is a Lebesgue space (which follows because  (resp.
(resp. 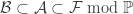 (if we identify
(if we identify  with
with  ). We’ll proceed without abuse of notation.
). We’ll proceed without abuse of notation.
 and
and  such that for any non-increasing choice
such that for any non-increasing choice  the intersection
the intersection  is a single point and that
is a single point and that  generates
generates 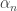 such that for all n we have
such that for all n we have 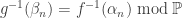 . We can assume that for each n all elements of
. We can assume that for each n all elements of  (and hence also those of
(and hence also those of 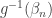 too) have positive measure. So we can ensure that all elements of
too) have positive measure. So we can ensure that all elements of  is non-decreasing modulo
is non-decreasing modulo  be the unique element in
be the unique element in  be the unique element in
be the unique element in  . Define H by
. Define H by  which is a well defined map from X to Y (which is because
which is a well defined map from X to Y (which is because  is measurable, moreover, equal to
is measurable, moreover, equal to  (where
(where  is the element corresponding to
is the element corresponding to 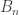 ).
).
 is an almost-everywhere defined measurable function. So we are comparing two a.e. defined measurable functions from
is an almost-everywhere defined measurable function. So we are comparing two a.e. defined measurable functions from 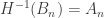 . Now notice that the set
. Now notice that the set ![[g \neq g']](https://s0.wp.com/latex.php?latex=%5Bg+%5Cneq+g%27%5D&bg=ffffff&fg=333333&s=0&c=20201002) is a subset of
is a subset of 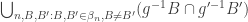 where the terms in the latter are null sets because of the previous sentence. We have shown
where the terms in the latter are null sets because of the previous sentence. We have shown 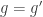 a.e..
a.e..
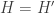 holds
holds 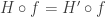 holds
holds ![[H = H']](https://s0.wp.com/latex.php?latex=%5BH+%3D+H%27%5D&bg=ffffff&fg=333333&s=0&c=20201002) is measurable (because
is measurable (because 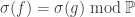 if and only if there are
if and only if there are  with
with  and
and 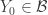 with
with  and a bi-measurable bijection
and a bi-measurable bijection  such that
such that  and
and  (measure preserving transformations on Lebesgue spaces), show that the latter is a factor of the former if and only if there is a joining
(measure preserving transformations on Lebesgue spaces), show that the latter is a factor of the former if and only if there is a joining 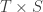 -invariant probability measure on
-invariant probability measure on  ) such that
) such that  mod
mod 